After more than eight months of research and development, Google has unveiled its most powerful A.I. so far. But only parts of it are widely available.
Google recently unveiled Gemini AI, its latest large language model, designed to be more powerful and capable than its predecessor. The new LLM comes in three sizes: Nano, Pro, and Ultra, catering to various needs of the users. Nano has been developed for fast on-device tasks, Pro serves as a versatile middle-tier, and Ultra is the most powerful. However, it is still undergoing safety checks and will be available next year.
Gemini comes in three sizes, Ultra, Pro and Nano, allowing it to run on anything ranging from mobile devices to data centers.
The rollout of Gemini to Bard will take place over two phases. Initially, Bard will be upgraded with a specifically tuned version of Gemini Pro. Next year, Google will introduce Bard Advanced, which will give users access to the best AI model, starting with Gemini Ultra.
The version of Bard with Gemini Pro will first become available in English in more than 170 countries and territories worldwide, with more languages and countries, including the EU and U.K., soon.

State-of-the-art performance
We’ve been rigorously testing our Gemini models and evaluating their performance on a wide variety of tasks. From natural image, audio and video understanding to mathematical reasoning, Gemini Ultra’s performance exceeds current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development.
With a score of 90.0%, Gemini Ultra is the first model to outperform human experts on MMLU (massive multitask language understanding), which uses a combination of 57 subjects such as math, physics, history, law, medicine and ethics for testing both world knowledge and problem-solving abilities.
Our new benchmark approach to MMLU enables Gemini to use its reasoning capabilities to think more carefully before answering difficult questions, leading to significant improvements over just using its first impression.
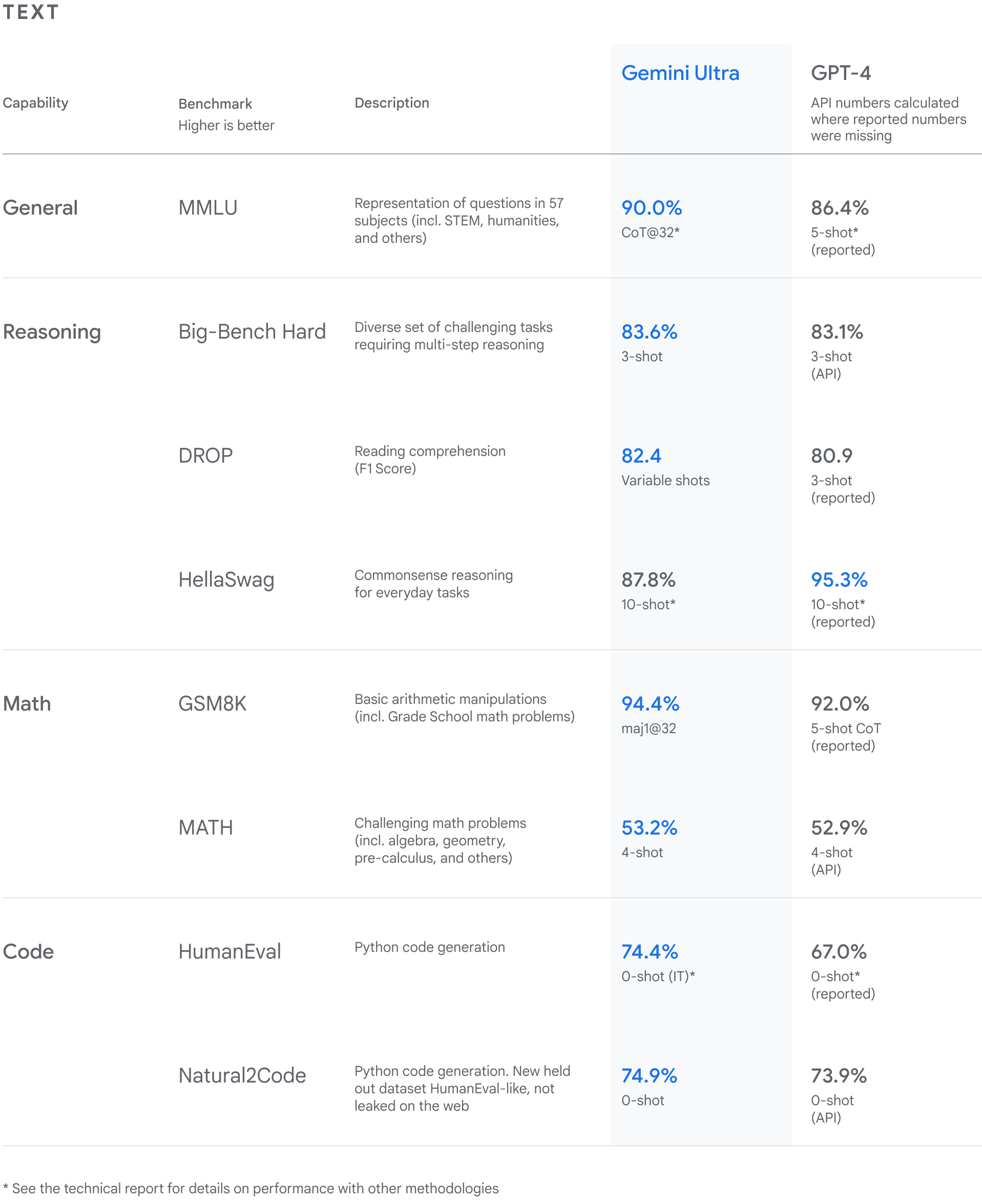
Gemini surpasses state-of-the-art performance on a range of benchmarks including text and coding.
Gemini Ultra also achieves a state-of-the-art score of 59.4% on the new MMMU benchmark, which consists of multimodal tasks spanning different domains requiring deliberate reasoning.
With the image benchmarks we tested, Gemini Ultra outperformed previous state-of-the-art models, without assistance from object character recognition (OCR) systems that extract text from images for further processing. These benchmarks highlight Gemini’s native multimodality and indicate early signs of Gemini’s more complex reasoning abilities.
See more details in our Gemini technical report.
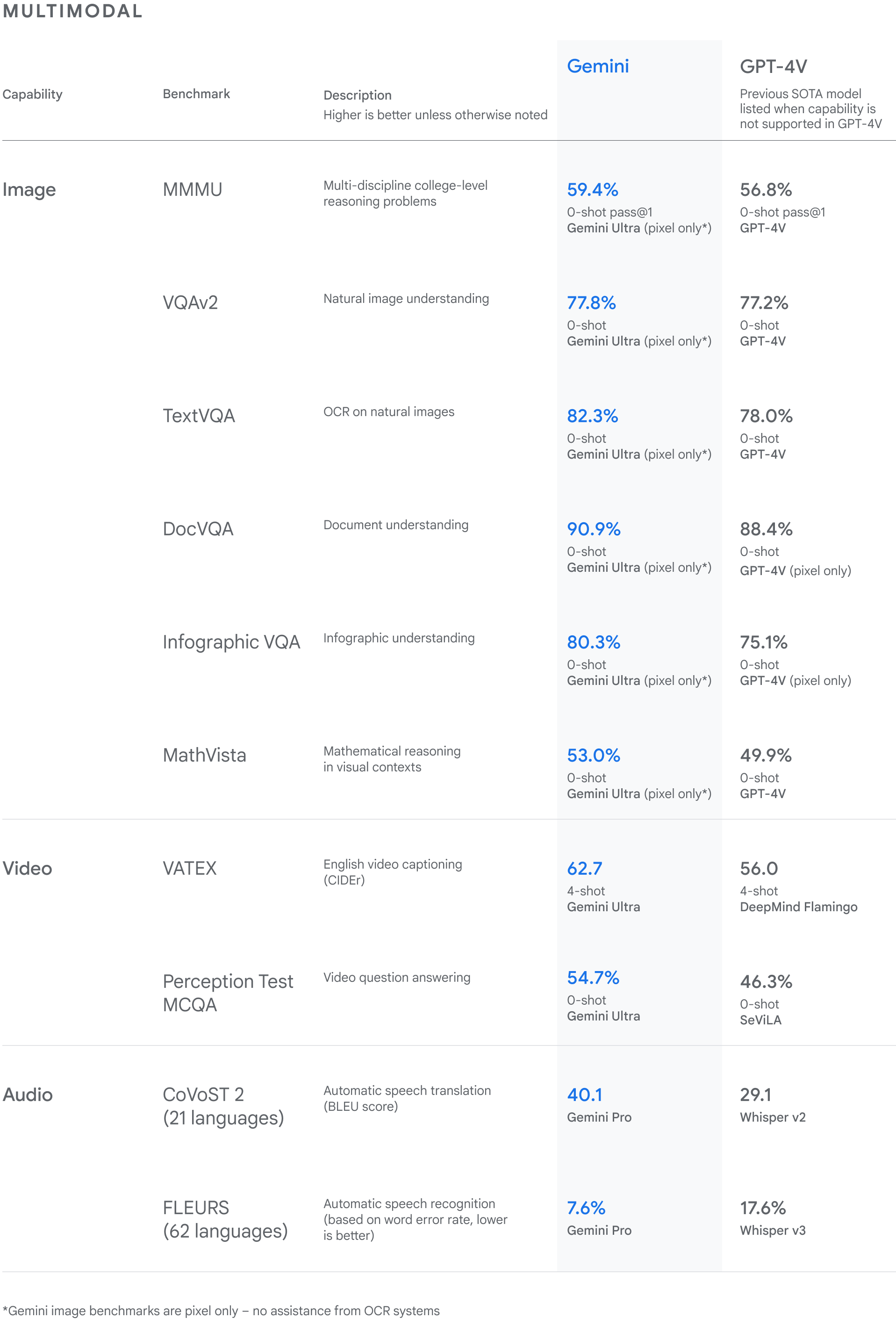
Gemini surpasses state-of-the-art performance on a range of multimodal benchmarks.
Next-generation capabilities
Until now, the standard approach to creating multimodal models involved training separate components for different modalities and then stitching them together to roughly mimic some of this functionality. These models can sometimes be good at performing certain tasks, like describing images, but struggle with more conceptual and complex reasoning.
We designed Gemini to be natively multimodal, pre-trained from the start on different modalities. Then we fine-tuned it with additional multimodal data to further refine its effectiveness. This helps Gemini seamlessly understand and reason about all kinds of inputs from the ground up, far better than existing multimodal models — and its capabilities are state of the art in nearly every domain.
Learn more about Gemini’s capabilities and see how it works.
Sophisticated reasoning
Gemini 1.0’s sophisticated multimodal reasoning capabilities can help make sense of complex written and visual information. This makes it uniquely skilled at uncovering knowledge that can be difficult to discern amid vast amounts of data.
Its remarkable ability to extract insights from hundreds of thousands of documents through reading, filtering and understanding information will help deliver new breakthroughs at digital speeds in many fields from science to finance.
Gemini unlocks new scientific insights
Understanding text, images, audio and more
Gemini 1.0 was trained to recognize and understand text, images, audio and more at the same time, so it better understands nuanced information and can answer questions relating to complicated topics. This makes it especially good at explaining reasoning in complex subjects like math and physics.
Gemini explains reasoning in math and physics
Advanced coding
Our first version of Gemini can understand, explain and generate high-quality code in the world’s most popular programming languages, like Python, Java, C++, and Go. Its ability to work across languages and reason about complex information makes it one of the leading foundation models for coding in the world.
Gemini Ultra excels in several coding benchmarks, including HumanEval, an important industry-standard for evaluating performance on coding tasks, and Natural2Code, our internal held-out dataset, which uses author-generated sources instead of web-based information.
Gemini can also be used as the engine for more advanced coding systems. Two years ago we presented AlphaCode, the first AI code generation system to reach a competitive level of performance in programming competitions.
Using a specialized version of Gemini, we created a more advanced code generation system, AlphaCode 2, which excels at solving competitive programming problems that go beyond coding to involve complex math and theoretical computer science.
Gemini excels at coding and competitive programming
When evaluated on the same platform as the original AlphaCode, AlphaCode 2 shows massive improvements, solving nearly twice as many problems, and we estimate that it performs better than 85% of competition participants — up from nearly 50% for AlphaCode. When programmers collaborate with AlphaCode 2 by defining certain properties for the code samples to follow, it performs even better.
We’re excited for programmers to increasingly use highly capable AI models as collaborative tools that can help them reason about the problems, propose code designs and assist with implementation — so they can release apps and design better services, faster.
See more details in our AlphaCode 2 technical report.
More reliable, scalable and efficient
We trained Gemini 1.0 at scale on our AI-optimized infrastructure using Google’s in-house designed Tensor Processing Units (TPUs) v4 and v5e. And we designed it to be our most reliable and scalable model to train, and our most efficient to serve.
On TPUs, Gemini runs significantly faster than earlier, smaller and less-capable models. These custom-designed AI accelerators have been at the heart of Google’s AI-powered products that serve billions of users like Search, YouTube, Gmail, Google Maps, Google Play and Android. They’ve also enabled companies around the world to train large-scale AI models cost-efficiently.
Today, we’re announcing the most powerful, efficient and scalable TPU system to date, Cloud TPU v5p, designed for training cutting-edge AI models. This next generation TPU will accelerate Gemini’s development and help developers and enterprise customers train large-scale generative AI models faster, allowing new products and capabilities to reach customers sooner.

A row of Cloud TPU v5p AI accelerator supercomputers in a Google data center.
Built with responsibility and safety at the core
At Google, we’re committed to advancing bold and responsible AI in everything we do. Building upon Google’s AI Principles and the robust safety policies across our products, we’re adding new protections to account for Gemini’s multimodal capabilities. At each stage of development, we’re considering potential risks and working to test and mitigate them.
Gemini has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity. We’ve conducted novel research into potential risk areas like cyber-offense, persuasion and autonomy, and have applied Google Research’s best-in-class adversarial testing techniques to help identify critical safety issues in advance of Gemini’s deployment.
To identify blindspots in our internal evaluation approach, we’re working with a diverse group of external experts and partners to stress-test our models across a range of issues.
To diagnose content safety issues during Gemini’s training phases and ensure its output follows our policies, we’re using benchmarks such as Real Toxicity Prompts, a set of 100,000 prompts with varying degrees of toxicity pulled from the web, developed by experts at the Allen Institute for AI. Further details on this work are coming soon.
To limit harm, we built dedicated safety classifiers to identify, label and sort out content involving violence or negative stereotypes, for example. Combined with robust filters, this layered approach is designed to make Gemini safer and more inclusive for everyone. Additionally, we’re continuing to address known challenges for models such as factuality, grounding, attribution and corroboration.
Responsibility and safety will always be central to the development and deployment of our models. This is a long-term commitment that requires building collaboratively, so we’re partnering with the industry and broader ecosystem on defining best practices and setting safety and security benchmarks through organizations like MLCommons, the Frontier Model Forum and its AI Safety Fund, and our Secure AI Framework (SAIF), which was designed to help mitigate security risks specific to AI systems across the public and private sectors. We’ll continue partnering with researchers, governments and civil society groups around the world as we develop Gemini.
It’s a very exciting time to be alive. All these amazing tools for everyone to use. If you are looking for AI developers in South Africa contact our team. We can also integrate existing AI tools into your website or application. Get in touch if you have an idea that you want to work on.



1 Comment
Jenny007 · 22nd November 2023 at 11:07 am
It really is amazing. I was lucky enough to get a beta invite to try it out. It is a game changer and will push the other models more. Very in depth post. Nice, will share it with my team.